data.table pt1
Разбор домашней работы
списки
- Код ниже создает иллюстрирует дисперсионный анализ. Прочитайте справки по
irisиaov. Выполните выражения.
Выведите на печать объект
aov_stats_summary. Выведите на печать и проанализируйте структуру объекта.***Выведите на печать уровень значимости (Pr(>F))
Решение. В списке aov_stat_summary неименованный подсписок. Этот подсписок является таблицей (data.frame). Соответственно, сначала нам надо обратиться к неименованному подсписку списка с помощью [[, а потом обратиться к первой строчке пятой колонки.
Либо использовать то, что таблицы – это тоже списки, и обратиться к значению в синтаксисе списков, а не колонок.
## List of 1
## $ :Classes 'anova' and 'data.frame': 2 obs. of 5 variables:
## ..$ Df : num [1:2] 2 147
## ..$ Sum Sq : num [1:2] 63.2 39
## ..$ Mean Sq: num [1:2] 31.606 0.265
## ..$ F value: num [1:2] 119 NA
## ..$ Pr(>F) : num [1:2] 1.67e-31 NA
## - attr(*, "class")= chr [1:2] "summary.aov" "listof"## [1] 1.669669e-31## [1] 1.669669e-31# так как мы умеем работать только с data.table
# конвертируем в data.table и извлекаем значение аналогично data.frame
library(data.table)
aov_stats <- as.data.table(aov_stats_summary[[1]])
str(aov_stats)## Classes 'data.table' and 'data.frame': 2 obs. of 5 variables:
## $ Df : num 2 147
## $ Sum Sq : num 63.2 39
## $ Mean Sq: num 31.606 0.265
## $ F value: num 119 NA
## $ Pr(>F) : num 1.67e-31 NA
## - attr(*, ".internal.selfref")=<externalptr>## Pr(>F)
## 1: 1.669669e-31## [1] 1.669669e-31таблицы. импорт данных
- подключите библиотеку data.table (установите, если не была установлена)
- скачайте файл titanic3.csv: https://gitlab.com/hse_mar/mar221s/-/raw/master/data/titanic3.csv.
- с помощью команды
titanic <- fread('titanic3.csv')импортируйте файл в рабочее окружение. Прочитайте справку по функцииfread()и попробуйте импортировать данные без явного сохранения на диск (не сработает с файлом в слаке).
- с помощью команды
# можно импортироватьс разу по ссылке
titanic <- fread('https://gitlab.com/hse_mar/mar221s/-/raw/master/data/titanic3.csv')- ** попробуйте написать код, в котором сначала происходит сохранение файла на диск, а потом чтение файла в рабочее окружение R (чтобы не руками сохранять, а кодом).
# можно сохранить объект по ссылка на диск
download.file(
'https://gitlab.com/hse_mar/mar221s/-/raw/master/data/titanic3.csv',
'titanic_new.csv'
)
# и потом прочитать с диска
titanic <- fread('titanic_new.csv')- посмотрите с помощью команды
class()объекта. Если он отличается отdata.table— преобразуйте в data.table с помощью функцииas.data.table()
## [1] "data.table" "data.frame"работа со строками
## pclass survived name sex age sibsp
## 1: 1 1 Allison, Master. Hudson Trevor male 0.92 1
## 2: 2 1 Caldwell, Master. Alden Gates male 0.83 0
## 3: 2 1 Hamalainen, Master. Viljo male 0.67 1
## 4: 2 1 Richards, Master. George Sibley male 0.83 1
## 5: 2 1 West, Miss. Barbara J female 0.92 1
## 6: 3 1 Aks, Master. Philip Frank male 0.83 0
## 7: 3 1 Baclini, Miss. Eugenie female 0.75 2
## 8: 3 1 Baclini, Miss. Helene Barbara female 0.75 2
## 9: 3 0 Danbom, Master. Gilbert Sigvard Emanuel male 0.33 0
## 10: 3 1 Dean, Miss. Elizabeth Gladys ""Millvina"" female 0.17 1
## 11: 3 0 Peacock, Master. Alfred Edward male 0.75 1
## 12: 3 1 Thomas, Master. Assad Alexander male 0.42 0
## parch ticket fare cabin embarked boat body
## 1: 2 113781 151.5500 C22 C26 S 11 NA
## 2: 2 248738 29.0000 S 13 NA
## 3: 1 250649 14.5000 S 4 NA
## 4: 1 29106 18.7500 S 4 NA
## 5: 2 C.A. 34651 27.7500 S 10 NA
## 6: 1 392091 9.3500 S 11 NA
## 7: 1 2666 19.2583 C C NA
## 8: 1 2666 19.2583 C C NA
## 9: 2 347080 14.4000 S NA
## 10: 2 C.A. 2315 20.5750 S 10 NA
## 11: 1 SOTON/O.Q. 3101315 13.7750 S NA
## 12: 1 2625 8.5167 C 16 NA
## home.dest
## 1: Montreal, PQ / Chesterville, ON
## 2: Bangkok, Thailand / Roseville, IL
## 3: Detroit, MI
## 4: Cornwall / Akron, OH
## 5: Bournmouth, England
## 6: London, England Norfolk, VA
## 7: Syria New York, NY
## 8: Syria New York, NY
## 9: Stanton, IA
## 10: Devon, England Wichita, KS
## 11:
## 12:## pclass survived name sex
## 1: 1 1 Allen, Miss. Elisabeth Walton female
## 2: 1 0 Allison, Mr. Hudson Joshua Creighton male
## 3: 1 0 Allison, Mrs. Hudson J C (Bessie Waldo Daniels) female
## 4: 1 1 Anderson, Mr. Harry male
## 5: 1 0 Andrews, Mr. Thomas Jr male
## ---
## 722: 3 0 Yasbeck, Mr. Antoni male
## 723: 3 0 Youseff, Mr. Gerious male
## 724: 3 0 Zakarian, Mr. Mapriededer male
## 725: 3 0 Zakarian, Mr. Ortin male
## 726: 3 0 Zimmerman, Mr. Leo male
## age sibsp parch ticket fare cabin embarked boat body
## 1: 29.0 0 0 24160 211.3375 B5 S 2 NA
## 2: 30.0 1 2 113781 151.5500 C22 C26 S 135
## 3: 25.0 1 2 113781 151.5500 C22 C26 S NA
## 4: 48.0 0 0 19952 26.5500 E12 S 3 NA
## 5: 39.0 0 0 112050 0.0000 A36 S NA
## ---
## 722: 27.0 1 0 2659 14.4542 C C NA
## 723: 45.5 0 0 2628 7.2250 C 312
## 724: 26.5 0 0 2656 7.2250 C 304
## 725: 27.0 0 0 2670 7.2250 C NA
## 726: 29.0 0 0 315082 7.8750 S NA
## home.dest
## 1: St Louis, MO
## 2: Montreal, PQ / Chesterville, ON
## 3: Montreal, PQ / Chesterville, ON
## 4: New York, NY
## 5: Belfast, NI
## ---
## 722:
## 723:
## 724:
## 725:
## 726:## pclass survived name sex age sibsp
## 1: 1 1 Allison, Master. Hudson Trevor male 0.92 1
## 2: 2 1 Caldwell, Master. Alden Gates male 0.83 0
## 3: 2 1 Hamalainen, Master. Viljo male 0.67 1
## 4: 2 1 Richards, Master. George Sibley male 0.83 1
## 5: 2 1 West, Miss. Barbara J female 0.92 1
## 6: 3 1 Aks, Master. Philip Frank male 0.83 0
## 7: 3 1 Baclini, Miss. Eugenie female 0.75 2
## 8: 3 1 Baclini, Miss. Helene Barbara female 0.75 2
## 9: 3 1 Dean, Miss. Elizabeth Gladys ""Millvina"" female 0.17 1
## 10: 3 1 Thomas, Master. Assad Alexander male 0.42 0
## parch ticket fare cabin embarked boat body
## 1: 2 113781 151.5500 C22 C26 S 11 NA
## 2: 2 248738 29.0000 S 13 NA
## 3: 1 250649 14.5000 S 4 NA
## 4: 1 29106 18.7500 S 4 NA
## 5: 2 C.A. 34651 27.7500 S 10 NA
## 6: 1 392091 9.3500 S 11 NA
## 7: 1 2666 19.2583 C C NA
## 8: 1 2666 19.2583 C C NA
## 9: 2 C.A. 2315 20.5750 S 10 NA
## 10: 1 2625 8.5167 C 16 NA
## home.dest
## 1: Montreal, PQ / Chesterville, ON
## 2: Bangkok, Thailand / Roseville, IL
## 3: Detroit, MI
## 4: Cornwall / Akron, OH
## 5: Bournmouth, England
## 6: London, England Norfolk, VA
## 7: Syria New York, NY
## 8: Syria New York, NY
## 9: Devon, England Wichita, KS
## 10:## pclass survived
## 1: 1 1
## 2: 1 1
## 3: 3 1
## 4: 3 0
## name sex
## 1: Cherry, Miss. Gladys female
## 2: Duff Gordon, Lady. (Lucille Christiana Sutherland) (""Mrs Morgan"") female
## 3: Dean, Miss. Elizabeth Gladys ""Millvina"" female
## 4: Sage, Miss. Constance Gladys female
## age sibsp parch ticket fare cabin embarked boat body
## 1: 30.00 0 0 110152 86.500 B77 S 8 NA
## 2: 48.00 1 0 11755 39.600 A16 C 1 NA
## 3: 0.17 1 2 C.A. 2315 20.575 S 10 NA
## 4: NA 8 2 CA. 2343 69.550 S NA
## home.dest
## 1: London, England
## 2: London / Paris
## 3: Devon, England Wichita, KS
## 4:## pclass survived
## 1: 1 1
## name sex
## 1: Duff Gordon, Lady. (Lucille Christiana Sutherland) (""Mrs Morgan"") female
## age sibsp parch ticket fare cabin embarked boat body home.dest
## 1: 48 1 0 11755 39.6 A16 C 1 NA London / Paris# альтернативнй вариант, когда учитываем пробел (' ' или '\\s')
titanic[grep('\\slady', name, ignore.case = TRUE)]## pclass survived
## 1: 1 1
## name sex
## 1: Duff Gordon, Lady. (Lucille Christiana Sutherland) (""Mrs Morgan"") female
## age sibsp parch ticket fare cabin embarked boat body home.dest
## 1: 48 1 0 11755 39.6 A16 C 1 NA London / ParisОсновная формула dt-синтаксиса
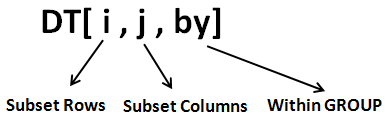
Общая формула data.table выглядит как dataset[выбор строк, операции над колонками, группировка]. То есть, указание, какие строки необходимо выделить, осуществляется в первой части (до первой запятой в синтаксисе data.table). Если нет необходимости выделять какие-то строки, перед первой запятой ничего не ставится. Параметр группировки (как и прочие параметры, кроме i и j - опциональны).
Также можно провести параллели с синтаксисом SQL-запроса. В терминах SQL data.table-выражения выглядят как таблица[where, select, group by].
Создание data.table-таблиц
Создать data.table можно следующим образом (синтаксис немного напоминает создание именованного списка, как и для всех форматов таблиц):
# подключаем пакет, если не был подключен ранее
library(data.table)
# создаем датасет
dt1 <- data.table(
month_names = month.name,
month_abb = month.abb,
month_ord = seq_len(length(month.abb)),
is_winter = grepl('Jan|Dec|Feb', month.abb)
)
print(dt1)## month_names month_abb month_ord is_winter
## 1: January Jan 1 TRUE
## 2: February Feb 2 TRUE
## 3: March Mar 3 FALSE
## 4: April Apr 4 FALSE
## 5: May May 5 FALSE
## 6: June Jun 6 FALSE
## 7: July Jul 7 FALSE
## 8: August Aug 8 FALSE
## 9: September Sep 9 FALSE
## 10: October Oct 10 FALSE
## 11: November Nov 11 FALSE
## 12: December Dec 12 TRUEВыбор строки
Выбор строк в data.table осуществляется аналогично выбору элементов в векторе: по номеру строки или по какому-то условию. При выборе по номеру строки также можно указать вектор номеров строк, которые необходимо вернуть. При выборке строки по условию проверяется, удовлетворяет ли условию каждый элемент строки в определенной колонке, и если удовлетворяет, выделяется вся строка.
## month_names month_abb month_ord is_winter
## 1: January Jan 1 TRUE# выбор по нескольким номерам строк
# сначала создаем вектор номеров строк
my_rows <- c(2, 5, 8)
# выводим строки, которые мы указали в векторе
dt1[my_rows]## month_names month_abb month_ord is_winter
## 1: February Feb 2 TRUE
## 2: May May 5 FALSE
## 3: August Aug 8 FALSE## month_names month_abb month_ord is_winter
## 1: February Feb 2 TRUE
## 2: May May 5 FALSE
## 3: August Aug 8 FALSEВыбор по условию: мы сразу указываем название колонки, к значениям которых будем применять условие-фильтр. Писать в стиле dt1[dt1$month_ord <= 3] избыточно, data.table понимает просто название колонки.
## month_names month_abb month_ord is_winter
## 1: January Jan 1 TRUE
## 2: February Feb 2 TRUE
## 3: March Mar 3 FALSEРабота с колонками
Обращение к колонке
В синтаксисе data.table все операции над колонками производятся после первой запятой. Выделение колонок также относится к операциям над колонками. Для выделения одной или нескольких колонок необходимо просто указать лист (список) с названиями колонки или колонок.
Если указать название колонки, то будут возвращены значения из этой колонки. Если название обернуть в list(), то будет возвращена таблица, с которой будет одна эта колонка:
## [1] "January" "February" "March" "April" "May" "June"
## [7] "July" "August" "September" "October" "November" "December"## month_names
## 1: January
## 2: February
## 3: March
## 4: April
## 5: May
## 6: June
## 7: July
## 8: August
## 9: September
## 10: October
## 11: November
## 12: DecemberЕсли посмотреть структуру, то оба объекта будут различаться - вектор строковых значений и таблица соответственно:
## chr [1:12] "January" "February" "March" "April" "May" "June" "July" ...## Classes 'data.table' and 'data.frame': 12 obs. of 1 variable:
## $ month_names: chr "January" "February" "March" "April" ...
## - attr(*, ".internal.selfref")=<externalptr>Выбор нескольких колонок
Если мы хотим на основе большой таблицы создать новую таблицу, с какими-то определенными колонками, мы их можем также перечислить в list():
## month_names month_abb
## 1: January Jan
## 2: February Feb
## 3: March Mar
## 4: April Apr
## 5: May May
## 6: June Jun
## 7: July Jul
## 8: August Aug
## 9: September Sep
## 10: October Oct
## 11: November Nov
## 12: December DecПри таком выделении можно сразу переименовывать колонки. Строго говоря, создается таблица с новой колонкой с требуемым именем, в которую записывается значения колонки, которую надо переименовать. Например:
# выделяем в отдельную таблицу колонку month_names, month_abb
# колонку month_names переименовываем в new_m_names
dt3 <- dt1[, list(new_m_names = month_names, month_abb)]
print(dt3)## new_m_names month_abb
## 1: January Jan
## 2: February Feb
## 3: March Mar
## 4: April Apr
## 5: May May
## 6: June Jun
## 7: July Jul
## 8: August Aug
## 9: September Sep
## 10: October Oct
## 11: November Nov
## 12: December DecCоздание колонок
Создать новую колонку в синтаксисе data.table можно с помощью оператора :=. Это точно такая же операция над колонками, как и все прочие, просто происходит создание новой колонки:
## month_names month_abb month_ord is_winter new_col
## 1: January Jan 1 TRUE 12
## 2: February Feb 2 TRUE 11
## 3: March Mar 3 FALSE 10
## 4: April Apr 4 FALSE 9
## 5: May May 5 FALSE 8
## 6: June Jun 6 FALSE 7
## 7: July Jul 7 FALSE 6
## 8: August Aug 8 FALSE 5
## 9: September Sep 9 FALSE 4
## 10: October Oct 10 FALSE 3
## 11: November Nov 11 FALSE 2
## 12: December Dec 12 TRUE 1Модификация колонок
Оператор := позволяет изменять объект на месте, поэтому мы можем просто колонке присвоить новое значение. Фактически мы на основе старой колонки создаем вектор новых значений и записываем его в в колонку с тем же названием.
## month_names month_abb month_ord is_winter new_col
## 1: January Jan 1 TRUE 17
## 2: February Feb 2 TRUE 16
## 3: March Mar 3 FALSE 15
## 4: April Apr 4 FALSE 14
## 5: May May 5 FALSE 13
## 6: June Jun 6 FALSE 12
## 7: July Jul 7 FALSE 11
## 8: August Aug 8 FALSE 10
## 9: September Sep 9 FALSE 9
## 10: October Oct 10 FALSE 8
## 11: November Nov 11 FALSE 7
## 12: December Dec 12 TRUE 6Можно совмещать фильтрацию по строкам и модификацию колонок. Например, для всех строк, где в колонке month_ord значения меньше или равны 5, в колонке new_col проставляем NA:
## month_names month_abb month_ord is_winter new_col
## 1: January Jan 1 TRUE NA
## 2: February Feb 2 TRUE NA
## 3: March Mar 3 FALSE NA
## 4: April Apr 4 FALSE NA
## 5: May May 5 FALSE NA
## 6: June Jun 6 FALSE 12
## 7: July Jul 7 FALSE 11
## 8: August Aug 8 FALSE 10
## 9: September Sep 9 FALSE 9
## 10: October Oct 10 FALSE 8
## 11: November Nov 11 FALSE 7
## 12: December Dec 12 TRUE 6Удаление колонок
Удаление колонок осуществляется схожим образом, просто колонке присваивается значение NULL
## month_names month_abb month_ord is_winter
## 1: January Jan 1 TRUE
## 2: February Feb 2 TRUE
## 3: March Mar 3 FALSE
## 4: April Apr 4 FALSE
## 5: May May 5 FALSE
## 6: June Jun 6 FALSE
## 7: July Jul 7 FALSE
## 8: August Aug 8 FALSE
## 9: September Sep 9 FALSE
## 10: October Oct 10 FALSE
## 11: November Nov 11 FALSE
## 12: December Dec 12 TRUEВычисления по одной колонке
Так как каждая колонка в табличке — это вектор, к ним можно применять все функции, которые могут быть применены к векторам:
# при создании новой колонки
dt1[, month_ord_sqrt := sqrt(month_ord)]
dt1[, new_col_1 := rnorm(.N)] # сэмпл из стандартного нормального распределения
dt1[, new_col_2 := runif(.N)] # сэмпл из равномерного распределения
# просто при вычислении какого-то значения
# вычисление общей длины таблицы
dt1[, .N]## [1] 12## [1] 0.3753465Группировка по нескольким полям
Часто возникает необходимость вычислений сразу по нескольким полям.
dt2 <- dt1[, list(
# всего строк
n_rows = .N,
# среднее по колонке new_col_1
new_col_1_mn = mean(new_col_1),
# медиана по колонке new_col_2
new_col_2_md = median(new_col_2)
)]
# в результате получаем вторую табличку
dt2## n_rows new_col_1_mn new_col_2_md
## 1: 12 -0.1897743 0.4151255.SD (Advanced)
Также можно выделить колонки таблицы data.table c помощью конструкций .SD и .SDcols. .SD служит ярлыком-указателем на колонки с которыми надо провести какое-то действие, а .SDcols - собственно вектор названий колонок или порядковых номеров колонок в таблице. Если .SDcols не указано, то подразумеваются все колонки таблицы. Оборачивать в list() конструкцию .SD не нужно.
Например:
## month_names month_abb month_ord is_winter month_ord_sqrt new_col_1
## 1: January Jan 1 TRUE 1.000000 -0.8628418
## 2: February Feb 2 TRUE 1.414214 -0.7699878
## 3: March Mar 3 FALSE 1.732051 -1.0632321
## 4: April Apr 4 FALSE 2.000000 -1.3508855
## 5: May May 5 FALSE 2.236068 1.1591956
## new_col_2
## 1: 0.03260952
## 2: 0.26642305
## 3: 0.48327842
## 4: 0.46380045
## 5: 0.02403901## month_names month_ord
## 1: January 1
## 2: February 2
## 3: March 3
## 4: April 4
## 5: May 5# выделяем эти же колонки по названиям
dt1[1:5, .SD, .SDcols = c('month_names', 'month_abb', 'month_ord')]## month_names month_abb month_ord
## 1: January Jan 1
## 2: February Feb 2
## 3: March Mar 3
## 4: April Apr 4
## 5: May May 5# выделяем эти же колонки по названиям, но паттерном 'month' и использованием grep
dt1[1:5, .SD, .SDcols = grep('month', names(dt1))]## month_names month_abb month_ord month_ord_sqrt
## 1: January Jan 1 1.000000
## 2: February Feb 2 1.414214
## 3: March Mar 3 1.732051
## 4: April Apr 4 2.000000
## 5: May May 5 2.236068# выделяем эти же колонки по названиям, но паттерном 'month' и функцией patterns из пакета data.table
dt1[1:5, .SD, .SDcols = patterns('month')]## month_names month_abb month_ord month_ord_sqrt
## 1: January Jan 1 1.000000
## 2: February Feb 2 1.414214
## 3: March Mar 3 1.732051
## 4: April Apr 4 2.000000
## 5: May May 5 2.236068.SD используется в большом количестве операций. Например, когда надо провести какую-то одну операцию над сразу несколькими колонками. Например, если мы хотим узнать, какого типа данные лежат в указанных колонках (пример искусственный, в реальности проще воспользоваться str()):
## month_names month_ord is_winter
## 1: character integer logicalПолезные ссылки
Моя серия вебинаров по data.table. Есть как запись, так и конспект. На занятиях мы будем рассматривать лишь половину или треть материала вебинаров.
Базовые операции одновременно в data.table и dplyr-синтаксисе. Много полезных приемов, и, в целом, наглядно. Смотрите блоки по data.table, dplyr синтаксис можно игнорировать или смотреть для общего развития (это весьма часто используемый синтаксис в академии).
Перевод документации data.table от Андрея Огурцова. Полезно для понимания разных нюансов работы data.table
Продвинутый data.table для желающих, много неочевидных нюансов и трюков.
Экзотические возможности и ключевые слова, для совсем экстремалов. Заметка важна в первую очередь внутренними ссылками на разные релевантные и поясняющие ресурсы.
Интересный сайт, где каждой конструкции в pandas дана аналогичная конструкция в data.table. Некоторые конструкции, правда, избыточны или переусложнены, но в целом сопоставление адекватное.
Домашнее задание
работа с колонками
- посчитайте средний возраст пассажиров в датасете titanic
- аналогично, посчитайте
summary()по возрасту женщин - выделите в отдельный датасет всех погибших пассажиров, оставьте для них только значения пола, возраста и класса билета (
pclass), переменнуюpclassпереименуйте вclass - ** cделайте это с помощью
.SD-синтаксиса и функцииsetnames() - в полученном датасете посчитайте количество пассажиров, их средний и медианный возраст, разброс по возрасту (
sd()) - *в датасете titanic попробуйте построить логистическую регрессию (lm или glm, обязательно прочитайте справку), которая бы предсказывала вероятность выживания пассажира (
survived). Возьмите все переменные как предиктор (формула будетsurvived ~ .). До решения следующего задания не смотрите на результат. - ** Попробуйте выбрать те предикторы, которые вам субъективно кажутся наиболее влияющими на вероятность выживания пассажира. Постройте регрессию по ним. Возможно, вам потребуется синтаксис формул.
- *** Сравните две модели – и просто по статистикам, и кодом (одна из полезных ссылок, остальные при необходимости погуглите сами)
для тех, кто любит посложнее
Создайте датасет:
- несколько пользователей
- по 5 сессий на каждого пользователя.
- поле логина, тип – дата и время (таймстамп), все логины в интервале 1-9 сентября. В юникс-формате или просто дата и время, на ваше усмотрение.
- для каждой сессии создайте случайную длину сессии (достаточно просто вектор длиной со всю таблицу, без учета пользователей) в секундах. Длина сессии должна варьировать в пределах 120 - 600 секунд
- посчитайте количество пользователей, среднее количество сессий на пользователя, среднюю длину сессий. Без учета вариативности внутри пользователя, overall по всему датасету.
Подсказки:
- датасет лучше создавать в несколько шагов
- есть полезная функция
expand.grid() - для генерации времени поможет функция
as.POSIXct(), плюс есть немного справочных материалов в учебнике: раз, два
## uid sid login_ts session_length
## 1: user_1 1 2023-09-01 01:59:07 464
## 2: user_1 2 2023-09-01 10:23:32 251
## 3: user_1 3 2023-09-01 18:38:58 526
## 4: user_1 4 2023-09-01 19:33:50 429
## 5: user_1 5 2023-09-01 21:24:17 200
## 6: user_2 1 2023-09-02 09:52:04 274Статистики:
## n_users total_sessions session_per_user session_length_mn
## 1: 3 15 5 413.5