Списки и таблицы
Векторы
Поиск по вхождению в массив
Нередко встречаются ситуации, когда необходимо выбрать значения вектора, которые присутствуют в другом векторе. Например, из списка группы студентов выбрать тех, кто указан в списке недопущенных к сессии. Для этого используется выражение x %in% y. Оператор %in% проверяет, встречается ли каждый элемент вектора х в векторе y. Как и в сравнении по условию, в результате получается логический вектор, который можно использовать для выделения элементов. Выделенные элементы можно записать в отдельный объект.
Например:
## [1] FALSE FALSE TRUE## [1] 2## num 2Поиск по строке
Для поиска по строковым записям (например, найти пользователя по ФИО, когда известно только имя) используют функцию grep() или grepl(). Первая функция возвращает номера элементов (или строк), в которых нашлось искомое строковое значение. Вторая функция возвращает результат проверки кадого элемента, включает ли он в себя искомый набор символов.
## [1] "January" "February" "March" "April" "May" "June"
## [7] "July" "August" "September" "October" "November" "December"## [1] 1 2 3 4 9 10 11 12## [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUEПервый аргумент — это паттерн регулярного выражения (если не используется аргумент fixed = TRUE):
vec <- c('user.1', 'user2')
# в регэкспах точка -- служебный символ, его надо экранировать двумя слэшами
vec[grep('\\.', vec)]## [1] "user.1"## [1] "user.1"Векторизованные операции
Векторизация — наверное, одна из самых примечательных и важных особенностей R как языка программирования и инструмента работы с данными. Фраза векторизованная функция означает, что операции производятся сразу над каждым элементом вектора. То есть там, где в других языках программирования (например, в Python) необходимо писать цикл или лямбда-функцию, в R можно просто передать вектор в аргументы функции.
Например, функция round(), если в качестве аргумента использовать вектор значений, округлит до нужного знака каждый элемент вектора:
## [1] -0.24325476 0.01592832 0.54399614 1.22622405 -0.15622975## [1] -0.243 0.016 0.544 1.226 -0.156В какой-то мере к векторизованным операциям можно отнести и простые арифметические операции над векторами. В частности, если мы попробуем сложить или умножить векторы одинаковой длины, то произойдет попарные сумма или произведение элементов векторов:
## [1] 1 5## [1] 7 9## [1] 8 14## [1] 7 45Recycling
В том случае, когда в операции используется два вектора разной длины, используется правило ресайклинга (recycling). То есть короткий вектор начинает использоваться с начала, и так до тех пор, пока длины векторов не сойдутся.
Например, мы хотим перемножить два вектора разной длины:
## [1] 1 2 3 4 5## [1] 3 5 7При перемножении операция элементы каждого вектора берутся попарно. Так как в векторе y всего три элемента, а в векторе x — пять, то элементы вектора y начинают использоваться повторно начиная с самого первого:
## Warning in x * y: longer object length is not a multiple of shorter object
## length## [1] 3 10 21 12 25При этом интерпретатор R нам выдаст предупреждение, что длины не совпадают:
Warning message:
In x * y : longer object length is not a multiple of shorter object lengthЕсли использовать два вектора кратной длины (например, 2 и 4 элемента), то короткий вектор будет переиспользован, но предупреждения не будет:
## [1] 1 10 3 20Если учесть, что в R нет скаляров и x <- 5 это создание вектора из одного элемента (единичного вектора), то умножение вектора на какое-то значение — то же самое умножение векторов с переиспользованием короткого вектора.
Изменение элементов объектов
В задачах на изменение значения элемента векторов, списков или таблиц используется следующая логика - указывается элемент объекта, с которым надо произвести какое-то действие, и этому элементу присваивается новое значение. Например, у нас есть вектор из 10 значений в случайном порядке от 1 до 10, и мы хотим возвести в квадрат третий элемент:
## int [1:10] 10 6 5 4 1 8 2 7 9 3## num [1:10] 10 6 25 4 1 8 2 7 9 3Создание новых элементов или удаление уже существующих производятся аналогично - указывается индекс элемента (или его название, если применимо), и присваивается какое-то значение. Для создания элемента - любой объект, если он не нарушает уже существующую структуру (например, в таблице на пять строк нельзя создать колонку с шестью значениями), если в векторе создавать значение иного типа, чем был, то все значения будут преобразованы к более общему по правилам преобразования.
## chr [1:10] "10" "6" "25" "4" "1" "8" "2" "7" "x" "3"Для удаления элемента вектора можно просто сделать переприсвоение этому объекту тех же значений, за исключением того, которое требуется удалить:
## chr [1:9] "10" "6" "4" "1" "8" "2" "7" "x" "3"Списки
Список элементов разных типов - векторов, таблиц, атомарных типов, других листов, функций и так далее. Длина и тип объекта в списке значения не имеет.
Создание списков
Для создания списка используется команда list(), где в аргументах через запятую перечисляются все элементы, которые необходимо включить в лист. Например:
x <- seq(from = 13, to = 0, by = -3)
y <- rep(x = 'c', times = 3)
z <- TRUE
my_list <- list(x, y, z)
str(my_list)## List of 3
## $ : num [1:5] 13 10 7 4 1
## $ : chr [1:3] "c" "c" "c"
## $ : logi TRUEИменованные списки
Помимо простого объединения объектов в списки и последующим вызовом элементов по номеру в списке, можно создавать именованные списки, где каждые элементы будут иметь заданное название. Например,
x <- seq(from = 13, to = 0, by = -3)
y <- rep(x = 'c', times = 3)
z <- TRUE
my_list <- list(seq_example = x,
rep_example = y,
atomic_example = z)
print(my_list)## $seq_example
## [1] 13 10 7 4 1
##
## $rep_example
## [1] "c" "c" "c"
##
## $atomic_example
## [1] TRUEВыбор элемента списка
Выбор элементов списка также использует выбор по номеру элемента. Следует учитывать, что для списков несколько различается поведение операторов [ и [[. Так, оператор [ позволяет выделить элемент списка в виде отдельного списка:
# создадим список
my_list <- list(seq_example = seq(from = 13, to = 0, by = -3),
rep_example = rep(x = 'c', times = 3),
atomic_example = TRUE)
str(my_list)## List of 3
## $ seq_example : num [1:5] 13 10 7 4 1
## $ rep_example : chr [1:3] "c" "c" "c"
## $ atomic_example: logi TRUE## List of 1
## $ seq_example: num [1:5] 13 10 7 4 1Оператор [[ позволяет вызвать значения вызываемых элементов списка. Так, my_list[[1]] вызовет не первый элемент в виде списка, а значения первого элемента в виде вектора (как они и были заданы):
# выберем значения первого элемента списка
first_element_values <- my_list[[1]]
str(first_element_values)## num [1:5] 13 10 7 4 1Также для именованных списков можно использовать выделение по имени элемента. Для указания элемента списка используется оператор $ и конструкция вида list_name$element_name. Например:
## $seq_example
## [1] 13 10 7 4 1
##
## $rep_example
## [1] "c" "c" "c"
##
## $atomic_example
## [1] TRUE## num [1:5] 13 10 7 4 1Структура объектов
Нередко при работе с разными объектами необходимо получить сводную информацию об объекте - класс объекта, иерархию элементов объекта, первые значения каждого элемента и так далее. Для этих целей используется функция str() (от structure), которая выводит каждый элемент объекта в виде вектора значений. Например, при просмотре структуры таблицы iris мы получаем класс объекта (data.frame), количество строк и столбцов, название колонок, тип элементов и первые десять значений каждой колонки:
## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...При просмотре структуры списка, который в качестве одного из элементов содержит другой список, точно также отображается каждый элемент списка, его тип, в том числе и типы и элементы вложенного списка. Вложенный список дополнительно выделен точками и отступом:
## List of 3
## $ e1: int [1:5] 1 2 3 4 5
## $ e2: chr [1:5] "a" "b" "c" "d" ...
## $ e3:List of 2
## ..$ e31: num [1:5] 0.983 -0.622 -0.732 -0.517 -1.751
## ..$ e32: num [1:5] 0.8106 0.5257 0.9147 0.8313 0.0458Таблицы
Таблица — это набор наблюдений по строкам и пространство признаков этих наблюдений в виде набора колонок. Базовый тип для табли в R - data.frame. На уровне структуры data.frame — это все те же списки, в которых могут храниться разные по типу объекты, однако с требованием равенства длины объектов. Важно: все значения одной колонки могут быть только одного типа (потому что это, по сути, векторы), а не как в Excel, OpenOffice или каком другом табличном процессоре.
data.frame vs data.table vs dplyr
Несмотря на то, что базовый тип таблиц это data.frame, в настоящее время используются варианты надстроек над этим типом: формат data.table или формат tibble из пактов data.table и dplyr соответственно. Различить их можно по элементам синтаксиса. В частности, data.frame почти всегда использует оператор $ (my_table$my_var), в data.table активно используется оператор :=, а в tibble - оператор %>%.
Пример создания таблицы и выбора строки по условию в data.frame:
# создаем таблицу
set.seed(1234)
df <- data.frame(
var1 = sample(letters, 5),
var2 = sample(1:5, 5)
)
# смотрим результат
print(df)## var1 var2
## 1 p 1
## 2 v 5
## 3 e 2
## 4 l 3
## 5 o 4## [1] "p" "v" "e" "l" "o"## var1 var2
## 1 p 1
## 3 e 2
## 4 l 3Аналогичные операции в tibble-формате:
set.seed(1234)
library(dplyr)
dp <- tibble(
var1 = sample(letters, 5),
var2 = sample(1:5, 5)
)
dp %>%
filter(var2 <= 3) ## # A tibble: 3 × 2
## var1 var2
## <chr> <int>
## 1 p 1
## 2 e 2
## 3 l 3data.table
Преимущества data.table
высокая скорость IO / манипуляций (бенчмарки)
параллелизация вычислений по умолчанию
опирается только на base R
лаконичность выражений
бережные апдейты
забота об обратной совместимости
Создание data.table-таблиц
Создать data.table можно следующим образом (синтаксис немного напоминает создание именованного списка, как и для всех форматов таблиц):
##
## Attaching package: 'data.table'## The following objects are masked from 'package:dplyr':
##
## between, first, last# создаем датасет
dt1 <- data.table(
month_names = month.name,
month_abb = month.abb,
month_ord = seq_len(length(month.abb)),
is_winter = grepl('Jan|Dec|Feb', month.abb)
)
print(dt1)## month_names month_abb month_ord is_winter
## 1: January Jan 1 TRUE
## 2: February Feb 2 TRUE
## 3: March Mar 3 FALSE
## 4: April Apr 4 FALSE
## 5: May May 5 FALSE
## 6: June Jun 6 FALSE
## 7: July Jul 7 FALSE
## 8: August Aug 8 FALSE
## 9: September Sep 9 FALSE
## 10: October Oct 10 FALSE
## 11: November Nov 11 FALSE
## 12: December Dec 12 TRUEОсновная формула dt-синтаксиса
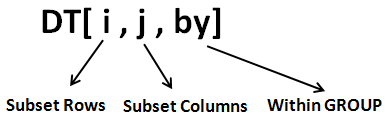
Общая формула data.table выглядит как dataset[выбор строк, операции над колонками, группировка]. То есть, указание, какие строки необходимо выделить, осуществляется в первой части (до первой запятой в синтаксисе data.table). Если нет необходимости выделять какие-то строки, перед первой запятой ничего не ставится. Параметр группировки (как и прочие параметры, кроме i и j - опциональны).
Также можно провести параллели с синтаксисом SQL-запроса. В терминах SQL data.table-выражения выглядят как таблица[where, select, group by].
Создание data.table-таблиц
Создать data.table можно следующим образом (синтаксис немного напоминает создание именованного списка, как и для всех форматов таблиц):
# подключаем пакет, если не был подключен ранее
library(data.table)
# создаем датасет
dt1 <- data.table(
month_names = month.name,
month_abb = month.abb,
month_ord = seq_len(length(month.abb)),
is_winter = grepl('Jan|Dec|Feb', month.abb)
)
print(dt1)## month_names month_abb month_ord is_winter
## 1: January Jan 1 TRUE
## 2: February Feb 2 TRUE
## 3: March Mar 3 FALSE
## 4: April Apr 4 FALSE
## 5: May May 5 FALSE
## 6: June Jun 6 FALSE
## 7: July Jul 7 FALSE
## 8: August Aug 8 FALSE
## 9: September Sep 9 FALSE
## 10: October Oct 10 FALSE
## 11: November Nov 11 FALSE
## 12: December Dec 12 TRUEВыбор строки
Выбор строк в data.table осуществляется аналогично выбору элементов в векторе: по номеру строки или по какому-то условию. При выборе по номеру строки также можно указать вектор номеров строк, которые необходимо вернуть. При выборке строки по условию проверяется, удовлетворяет ли условию каждый элемент строки в определенной колонке, и если удовлетворяет, выделяется вся строка.
## month_names month_abb month_ord is_winter
## 1: January Jan 1 TRUE# выбор по нескольким номерам строк
# сначала создаем вектор номеров строк
my_rows <- c(2, 5, 8)
# выводим строки, которые мы указали в векторе
dt1[my_rows]## month_names month_abb month_ord is_winter
## 1: February Feb 2 TRUE
## 2: May May 5 FALSE
## 3: August Aug 8 FALSE## month_names month_abb month_ord is_winter
## 1: February Feb 2 TRUE
## 2: May May 5 FALSE
## 3: August Aug 8 FALSEВыбор по условию: мы сразу указываем название колонки, к значениям которых будем применять условие-фильтр. Писать в стиле dt1[dt1$month_ord <= 3] избыточно, data.table понимает просто название колонки.
## month_names month_abb month_ord is_winter
## 1: January Jan 1 TRUE
## 2: February Feb 2 TRUE
## 3: March Mar 3 FALSEДополнительные материалы
Получение информации об объекте
Моя серия вебинаров по data.table. Есть как запись, так и конспект. На занятиях мы будем рассматривать лишь половину или треть материала вебинаров.
Базовые операции одновременно в data.table и dplyr-синтаксисе. Много полезных приемов, и, в целом, наглядно. Смотрите блоки по data.table, dplyr синтаксис можно игнорировать или смотреть для общего развития (это весьма часто используемый синтаксис в академии).
Перевод документации data.table от Андрея Огурцова. Полезно для понимания разных нюансов работы data.table
Продвинутый data.table для желающих, много неочевидных нюансов и трюков.
Экзотические возможности и ключевые слова, для совсем экстремалов. Заметка важна в первую очередь внутренними ссылками на разные релевантные и поясняющие ресурсы.
Интересный сайт, где каждой конструкции в pandas дана аналогичная конструкция в data.table. Некоторые конструкции, правда, избыточны или переусложнены, но в целом сопоставление адекватное.
Домашнее задание
векторы
Умножьте каждый элемент вектора
vec <- sample(10)на 2.Вычислите корень из каждого элемента вектора
vec. Округлите значения до второго знака. В принципе для этого достаточно выражения длиной в 16 символов.выполните выражение
paste('blabla', 1:3, letters [1:2], month.abb[1:4]). Разберитесь, почему получился такой результат.
списки
- Код ниже создает иллюстрирует дисперсионный анализ. Прочитайте справки по
irisиaov. Выполните выражения.
Выведите на печать объект
aov_stats_summary. Выведите на печать и проанализируйте структуру объекта.***Выведите на печать уровень значимости (Pr(>F))
таблицы. импорт данных
- подключите библиотеку data.table (установите, если не была установлена)
- скачайте файл titanic3.csv: https://gitlab.com/hse_mar/mar221s/-/raw/master/data/titanic3.csv.
- с помощью команды
titanic <- fread('titanic3.csv')импортируйте файл в рабочее окружение. Прочитайте справку по функцииfread()и попробуйте импортировать данные без явного сохранения на диск (не сработает с файлом в слаке).
- с помощью команды
- ** попробуйте написать код, в котором сначала происходит сохранение файла на диск, а потом чтение файла в рабочее окружение R (чтобы не руками сохранять, а кодом).
- посмотрите с помощью команды
class()объекта. Если он отличается отdata.table— преобразуйте в data.table с помощью функцииas.data.table()